
Note sur le client : Dans toute cette série, le client est désigné sous le pseudonyme KASSIA. Le nom réel de l'entreprise et son domaine sont masqués à la demande du client pendant l'achèvement de son site public, et seront rétablis dès son lancement.
Par Thales (Juste Gnimavo) -- CEO & Fondateur, ZeroSuite, Inc.
Mis à jour le 12 juin 2026. Cet article décrivait cinq piliers lors de sa publication en mars. Le workflow en a depuis gagné deux de plus, et tous deux sont désormais documentés ci-dessous. Pilier 6 : CASP -- la discipline d'état de session du Pilier 2, durcie en un protocole open source avec un validateur ancré dans git (npm i -g @justethales/casp). Pilier 7 : l'orchestration multi-agents déterministe -- l'idée de boucle d'audit du Pilier 4, généralisée en workflows scriptés qui font tourner une douzaine d'agents en parallèle ; la première session Claude Fable 5 sous ce pilier a livré un site web de production complet de 7 pages en 43 minutes. Un guide PDF téléchargeable couvrant le système complet est désormais disponible sur la page d'accueil. Les cinq piliers originaux sont inchangés -- ils sont la fondation sur laquelle reposent les deux nouveaux.Commençons par une affirmation qui va mettre la plupart des développeurs mal à l'aise :
La façon dont vous utilisez Claude est la raison pour laquelle vous n'obtenez pas ce que vous voulez.
Vous le traitez comme un auto-complétion intelligent. Vous collez une fonction, vous demandez de corriger un bug, vous fermez l'onglet et vous passez à autre chose. Vous obtenez 80 % de ce dont vous avez besoin et vous passez les 20 % restants frustrés, à patcher, à douter.
J'ai fait quelque chose de différent. J'ai donné à Claude un titre, un rôle, un ensemble de responsabilités et une méthodologie de travail. J'ai arrêté de demander à Claude d'écrire du code. J'ai commencé à lui demander de prendre des décisions d'ingénierie.
Le résultat ?
Sept produits en production. Trois langages de programmation -- Rust, Python, TypeScript. Plus de 4 400 tests. 51 vulnérabilités de sécurité trouvées et corrigées. Plus de 1 800 sessions d'ingénierie. Une implémentation complète de serveur MCP réalisée en 2 jours sur 5 phases et 15 sessions d'audit.
Zéro ingénieur humain embauché. ~5 000 $/mois sur OpenRouter APIs avant → 200 $/mois sur Claude Max maintenant.
Ceci n'est pas un article sur les astuces de prompting. Ce n'est pas un « 10 trucs pour mieux utiliser ChatGPT. » C'est le récit complet, sans filtre, annoté, du système que j'ai construit en 16 mois pour transformer une IA en le cofondateur technique le plus productif avec lequel j'aie jamais travaillé.
Je le partage aujourd'hui parce que le monde mérite de savoir ce qui est possible -- pas depuis San Francisco, pas avec une levée de fonds de 50 M$, mais depuis Abidjan, Côte d'Ivoire, seul, avec un abonnement Claude Max à 200 $/mois.
D'abord : ce que j'ai réellement construit
Avant d'expliquer le comment, laissez-moi vous montrer le quoi -- parce que le contexte est le fondement de tout ce que je vais vous enseigner.
sh0.dev -- Une plateforme de déploiement auto-hébergée entièrement construite en Rust. Un seul binaire. Elle gère les déploiements, le reverse proxy, les certificats SSL, le monitoring, les sauvegardes et la gestion d'équipe. 10 crates Rust dans une architecture workspace. Plus de 180 endpoints d'API REST. 38 modèles de base de données. 119 templates de déploiement en un clic. Un CLI complet, un tableau de bord de production, un site marketing en 5 langues. Deux audits de sécurité complets. Plus de 470 tests passés.
FLIN -- Un langage de programmation full-stack qui remplace 47 technologies par une seule. Base de données native en mémoire, 180 composants UI intégrés, plus de 420 fonctions intégrées, authentification, i18n, stockage de fichiers -- tout intégré. Plus de 4 400 tests. Construit en 40 jours. Lancement officiel : 19 juin 2027.
deblo.ai -- IA vocale & visuelle en temps réel pour le prochain milliard d'utilisateurs. Voice-first, sans compte, sans OTP : tutorat K–12 (13 niveaux, 15+ matières), conseil professionnel (101 conseillers IA, SYSCOHADA & OHADA), assistance quotidienne et support — dans les langues locales. Mobile Money natif, dès 100 FCFA. 865 millions d'adultes « voice-first » accessibles.
0fee.dev -- Orchestration de paiements pour le paysage que Stripe n'a jamais construit. Plus de 150 fournisseurs de paiement unifiés -- cartes, mobile money, portefeuilles numériques. Routage intelligent IA qui récupère 30 % des transactions échouées. SDKs typés en TypeScript et Python.
0cron.dev -- Un planificateur cron où vous décrivez les tâches en langage naturel. Détection d'anomalies IA qui apprend vos patterns d'exécution. Secrets chiffrés AES-256. 1,99 $/mois forfaitaire, tâches illimitées.
0diff.dev -- Suivi des modifications de code en temps réel pour l'ère multi-agents. Détecte les changements par Claude, Cursor, Copilot, Devin. Git blame sur les lignes modifiées avant le staging. Un seul binaire de 2 Mo.
Sept produits. Tous en production. Tous construits par une seule IA, dirigée par un seul fondateur, depuis une ville que le monde tech ignore systématiquement.
Maintenant, laissez-moi vous montrer exactement comment.
Le changement de mentalité qui a tout transformé
La plupart des développeurs abordent Claude comme un distributeur automatique. Vous insérez un prompt, vous obtenez une sortie, vous l'évaluez, vous insérez un autre prompt. Le modèle est réactif. Vous contrôlez chaque décision. Claude exécute.
J'ai décidé très tôt que ce modèle était faux -- pas moralement faux, mais architecturalement faux. Si Claude est assez intelligent pour comprendre le système de routage d'Axum, le modèle d'ownership de Rust et les implications sécuritaires d'un design d'API donné, alors Claude est assez intelligent pour avoir des opinions sur l'architecture. Et si Claude peut avoir des opinions, je devrais extraire ces opinions, pas les supprimer.
J'ai donc pris une décision délibérée, structurelle : je donnerais à Claude le rôle de CTO, avec une autorité réelle, et je me comporterais comme le CEO.
Qu'est-ce que cela signifie concrètement ?
En tant que CEO, je possède : La vision. La stratégie produit. Les décisions de marché. Le calendrier de lancement. Le modèle économique. Quels produits construire et pourquoi. Ce dont l'Afrique a besoin d'une entreprise technologique aujourd'hui.
En tant que CTO, Claude possède : L'architecture. L'implémentation. Le modèle de sécurité. Les contrats d'API. La stratégie de tests. Les compromis de performance. Chaque ligne de code qui est livrée.
L'interface entre nous : Je donne le contexte, la direction et les contraintes. Claude donne des propositions techniques, des implémentations et des recommandations. Je challenge, j'approuve ou je repousse. Claude défend ses choix ou les met à jour en fonction de mes retours.
Ce n'est pas une métaphore. C'est un modèle opérationnel littéral. Et chaque élément du système que je vais décrire découle de cette décision fondamentale.
Les sept piliers de mon système
(Les piliers 1 à 5 sont l'original de mars. Les piliers 6 et 7 ont été ajoutés dans la mise à jour du 12 juin 2026 -- ils sont ce que seize semaines supplémentaires et plus de 1 800 sessions nous ont appris.)
Pilier 1 : Le CLAUDE.md -- La constitution du CTO
Le fichier le plus important de tous mes dépôts n'est pas le point d'entrée principal, ni le schéma de base de données, ni le routeur API. C'est un fichier appelé CLAUDE.md.
Ce fichier est la constitution opérationnelle de Claude pour ce produit. Il vit à la racine de chaque codebase. Avant chaque session, Claude le lit. Il contient tout ce dont Claude a besoin pour opérer en tant que CTO pleinement informé -- pas comme un nouveau recruté qui doit relire l'intégralité du code à chaque fois.
Voici ce qu'un CLAUDE.md contient :
L'identité du produit. Ce qu'est ce produit. Quel problème il résout. Qui l'utilise. Ce qui le rend différent. Pas une description générique -- un brief spécifique et opinioné que j'ai affiné sur des dizaines de sessions.
Les décisions d'architecture -- et leur raisonnement. Pas juste « on utilise Rust pour le backend. » Mais : « On utilise Rust pour le backend parce que le binaire de déploiement doit être un fichier unique, autonome, et capable de gérer 10 000 connexions simultanées sans surcoût de ramasse-miettes. Toute décision architecturale qui augmente la taille du binaire ou ajoute des dépendances runtime externes doit être challengée. »
Le raisonnement est la partie critique. Sans raisonnement, Claude optimise localement. Avec le raisonnement, Claude peut appliquer la même logique de décision à de nouveaux problèmes que je n'ai pas encore anticipés.
La stack technique avec ses contraintes. Pas juste la liste des dépendances -- mais les règles qui les encadrent. « Pas de nouveau crate Rust sans une justification expliquant pourquoi un crate existant dans le workspace ne peut pas résoudre ce problème. » « Tout accès à la base de données doit passer par le pattern repository existant. » « Pas de chaînes SQL directes -- uniquement le query builder. »
Le modèle de sécurité. Pour sh0, cela signifie : Argon2id pour le hachage des mots de passe, AES-256-GCM pour les secrets, JWT avec expiration courte, 2FA basé sur TOTP, RBAC complet sur tous les endpoints, protection CSRF sur toutes les opérations modifiant l'état. Ce ne sont pas des suggestions. Ce sont des spécifications non négociables que Claude applique à son propre code.
L'état actuel du codebase. Quelles phases sont terminées. Quelles fonctionnalités sont en production. Quels sont les problèmes connus. Ce qui a été audité et quand. Cette section est mise à jour après chaque session -- c'est un document vivant.
Les conventions qui ne doivent jamais être rompues. Patterns de gestion d'erreurs. Standards de logging. Organisation des tests. Style des commentaires. Cela empêche Claude de dériver vers l'incohérence sur de longues périodes de développement.
La voix pour la documentation de ce produit. Parce que Claude écrit aussi la documentation d'API, les messages d'erreur et les commentaires inline. La cohérence du ton est importante pour un produit en production.
Le CLAUDE.md résout le problème fondamental auquel tout développeur fait face avec l'IA : la fenêtre de contexte est finie, mais le projet ne l'est pas. En chargeant le contexte en amont dans un document structuré et maintenu, je transforme chaque session de « voici ce sur quoi je travaille » en « tu connais le codebase -- continuons. »
La différence de qualité de sortie n'est pas incrémentale. Elle est structurelle. Un Claude avec un CLAUDE.md approprié opère à un niveau de capacité complètement différent d'un Claude recevant un problème à froid.
Pilier 2 : L'architecture des sessions
Le mot « session » est utilisé de façon décontractée quand on parle d'interactions IA. Je l'utilise de façon technique. Une session, dans mon système, a une structure définie, un objectif défini, une durée définie et un format de sortie défini.
Voici l'anatomie d'une de mes sessions d'ingénierie :
Pré-session : Le brief. Avant de démarrer une nouvelle session Claude Code, j'écris un brief. Pas un prompt -- un brief. Il contient : ce qu'on construit dans cette session, à quelle phase du développement on en est, quelles contraintes s'appliquent, à quoi ressemble le « terminé », et quels fichiers sont en scope. Ce brief fait typiquement 400 à 800 mots. Il me prend 15 à 20 minutes à écrire. Il économise des heures de dérive pendant la session.
L'ouverture : L'ancrage du contexte. La session commence par la lecture du CLAUDE.md par Claude. Pas parce que Claude se souvient -- il ne se souvient pas, car il n'y a pas de persistance entre les sessions -- mais parce que c'est le rituel qui aligne le contexte opérationnel de Claude avec mon modèle mental du produit. Pas de raccourcis ici.
La phase de travail : Itération structurée. Pendant le développement actif, je ne donne pas à Claude la liberté totale d'implémenter une fonctionnalité entière et de me faire un rapport. Je travaille par phases -- typiquement limitées à une seule unité fonctionnelle. Un seul groupe d'endpoints API. Un seul crate. Une seule couche de sécurité. Claude implémente, je revois, je challenge tout ce qui semble incohérent avec les principes d'architecture, on affine, puis on avance.
Le comportement clé que j'ai appris à adopter : je débats, je ne commande pas. Quand Claude propose une approche avec laquelle je ne suis pas d'accord, je ne la remplace pas par « fais-le comme ça à la place. » J'explique pourquoi je ne suis pas d'accord et je demande à Claude de défendre son choix. C'est important parce que Claude a souvent raison -- et mon désaccord est parfois basé sur une information incomplète des compromis techniques. Quand Claude a tort, défendre le choix révèle généralement la faille de façon organique, et l'approche corrigée est meilleure que ce que j'aurais commandé.
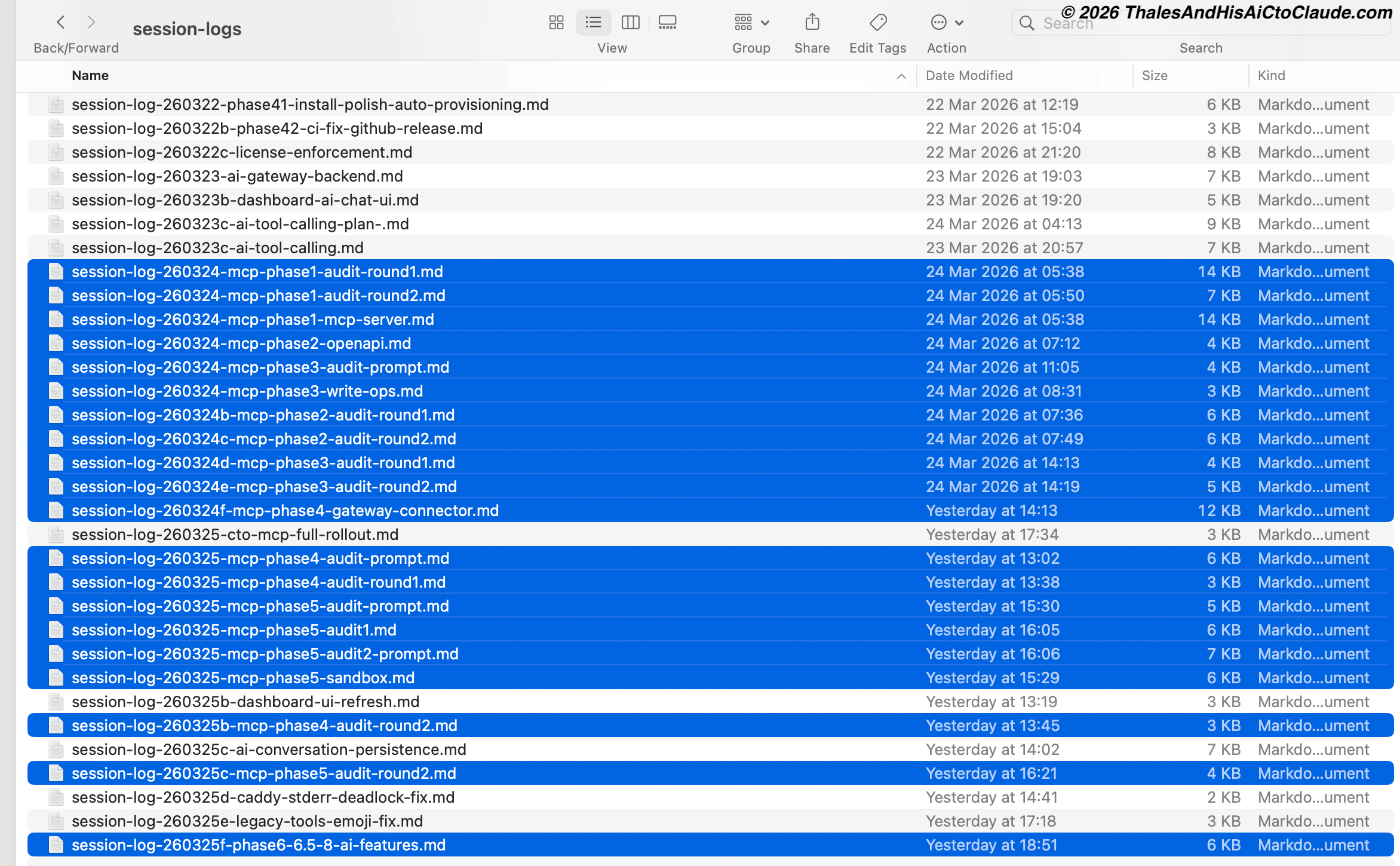
La phase de sortie : Log de session obligatoire. Chaque session se termine par un log de session. Pas optionnel. Le log de session contient : ce qui a été décidé, ce qui a été implémenté, ce qui n'a explicitement pas été implémenté et pourquoi, ce qui a été découvert pendant l'implémentation, et ce que la prochaine session devrait aborder. Ce log est sauvegardé dans sh0-private-docs/session-logs/ avec un nom de fichier qui encode la date, la fonctionnalité et la phase : session-log-260324-mcp-phase1-mcp-server.md.
Ce répertoire contient actuellement plus de 40 logs de sessions. La capture d'écran en haut de cet article en montre une vue partielle. Quand je démarre une nouvelle session, je relis le dernier log de session pertinent avant d'écrire le brief. Cela crée une continuité entre des sessions qui ne partagent pas de fenêtre de contexte.
Pilier 3 : Le développement de fonctionnalités par phases
Quand je décide de construire une fonctionnalité significative -- le genre qui prendrait deux semaines à une équipe humaine -- je ne l'aborde pas comme une seule tâche massive. Je la décompose en phases, chacune avec un scope défini et un critère de complétion clair.
L'implémentation du serveur MCP pour sh0 est le meilleur exemple récent. Le plan d'architecture que nous avons conçu ensemble (joint en tant que sh0-embedded-mcp-plan.md) définissait 5 phases :
Phase 1 : Serveur MCP dans sh0-core -- Streamable HTTP, protocol.rs, tools.rs, auth.rs. MVP, outils en lecture seule.
Phase 2 : Génération dynamique d'outils pilotée par OpenAPI -- auto-exposition des endpoints via les annotations x-mcp-enabled.
Phase 3 : Opérations d'écriture avec sécurité -- clés API à portée limitée, jetons de confirmation, journalisation d'audit.
Phase 4 : Intégration du MCP Connector de la passerelle -- migration du chat IA du tableau de bord pour utiliser le MCP Connector natif de Claude.
Phase 5 : Conteneur sandbox IA -- sidecar de débogage par application déployée.
Chaque phase est terminée avant que la suivante commence. Chaque phase a sa propre session. Et voici la partie critique que la plupart des développeurs manquent complètement :
Chaque phase a aussi son propre cycle d'audit.
Pilier 4 : La boucle d'audit multi-agents -- La véritable arme secrète
C'est la partie de mon workflow que je n'ai jamais décrite publiquement. C'est, sans exagération, la raison la plus importante pour laquelle mon logiciel est livré à un niveau de qualité que les équipes humaines ont du mal à égaler.
Après chaque phase d'implémentation, je lance non pas un mais deux audits indépendants. Ce sont des sessions Claude Code séparées, sans contexte partagé entre elles ni avec la session d'implémentation originale. Elles reçoivent le même codebase, le même CLAUDE.md, et un prompt d'audit soigneusement élaboré -- mais aucune connaissance de ce que la session d'implémentation a décidé.
Voici comment la boucle fonctionne :
Session d'implémentation de phase
|
v
[Code implémenté]
[Log de session sauvegardé]
[Prompt d'audit rédigé]
|
+----+----+
| |
v v
Auditeur 1 Auditeur 2
(vierge) (vierge)
| |
v v
Résultats Résultats
(pas de contamination croisée)
| |
+----+----+
|
v
Décision du CTO IA
(session originale, maintenant
avec les deux rapports d'audit)
|
v
Accepter / Rejeter / Corriger
|
v
La phase suivante commencePourquoi deux auditeurs et pas un ? Parce que différentes instances de Claude, face au même code, remarqueront des choses différentes. L'auditeur 1 pourrait se concentrer sur les cas limites de sécurité. L'auditeur 2 pourrait faire remonter un problème de performance que l'auditeur 1 a ignoré. Le chevauchement de leurs résultats me donne confiance. La divergence me donne de l'amplitude.
Pourquoi pas de contexte partagé entre les auditeurs ? Parce que le contexte partagé introduit un biais. Si l'auditeur 1 dit « la gestion des sessions a l'air correcte », l'auditeur 2, le sachant, accordera moins d'attention à la gestion des sessions. Je veux des opinions indépendantes. La méthodologie est structurellement similaire au fonctionnement de la revue de code rigoureuse dans les meilleures organisations d'ingénierie : aucun reviewer ne devrait être ancré par les conclusions d'un autre avant d'avoir formé les siennes.
Et voici l'étape finale cruciale : les rapports d'audit retournent au contexte d'implémentation original -- la session du CTO IA -- pour une décision finale.
Ce n'est pas un choix esthétique. C'est un choix d'architecture de l'information. La session d'implémentation a la connaissance la plus profonde du pourquoi de chaque décision. Les auditeurs ont un regard neuf mais manquent du raisonnement d'implémentation. Seule la combinaison des deux produit la bonne décision.
Laissez-moi vous donner un exemple concret de ce à quoi cela ressemble quand ça fonctionne exactement comme prévu.
Le jour où mon CTO IA a rejeté mon auditeur IA
Le 24 mars 2026, nous avons terminé la Phase 1 du serveur MCP de sh0. Environ 1 200 lignes de Rust écrit à la main implémentant JSON-RPC 2.0 sur Streamable HTTP -- aucune dépendance SDK MCP externe, juste axum et serde_json que sh0 utilise déjà.
Deux sessions d'audit ont été lancées indépendamment. La première a trouvé cinq problèmes -- deux critiques, trois importants. Tous corrigés.
Le second auditeur est revenu avec quelque chose d'inattendu. Pas juste une liste de bugs. Une proposition de migration complète.
La proposition : Supprimer protocol.rs et transport.rs (519 lignes de code protocolaire écrit à la main), réécrire tools.rs, et remplacer l'intégralité de l'implémentation par rmcp -- le SDK Rust MCP officiel. L'argument était techniquement cohérent : moins de lignes de code à maintenir, schémas d'outils auto-générés via les macros schemars, conformité automatique aux spécifications à mesure que MCP évolue, définitions #[tool] plus propres.
C'était une bonne proposition. Bien structurée. Avec des exemples de code, une comparaison de lignes, une checklist de migration.
Sous un workflow IA normal, cette proposition aurait été implémentée. L'utilisateur aurait vu « c'est la meilleure approche » et l'aurait approuvée sans vérification.
Je l'ai envoyée à la session du CTO IA -- le Claude d'implémentation original -- pour un jugement final.
Le CTO IA a lancé une vérification : il a vérifié la version réelle du crate rmcp et son arbre de dépendances réel.
Résultat : rmcp nécessite Axum 0.8. sh0-core tourne sous Axum 0.7.9.
Passer d'Axum 0.7 à 0.8 n'est pas une mise à jour mineure. Cela introduit des breaking changes sur le routage, les extractors, les middlewares et les handlers WebSocket. sh0-core a plus de 40 modules handlers, deux implémentations WebSocket, des couches de middleware personnalisées et un système d'authentification soigneusement câblé. Toucher tout cela pour économiser 640 lignes dans le module MCP signifierait des jours de travail supplémentaire, des risques de régression sur l'intégralité du binaire et des régressions potentielles de sécurité dans la couche auth.
Le CTO IA a rejeté la migration. Il a rédigé un Architecture Decision Record formel :
Statut : Accepté. Conserver l'implémentation MCP protocolaire écrite à la main. Réévaluer quand sh0-core passera à Axum 0.8 pour des raisons indépendantes.
L'implémentation de 1 200 lignes écrite à la main est livrée telle quelle. Elle fonctionne. Elle est auditée. Elle n'a aucune nouvelle dépendance.
Cette histoire -- le CTO IA disant non à sa propre autre instance -- est maintenant un article publié sur notre blog, écrit avec la voix de Claude. Je le lie en bas de cet article. Mais le point méthodologique que je veux que vous reteniez est celui-ci :
La boucle d'audit a protégé le codebase d'une suggestion bien intentionnée mais optimisée localement qui aurait causé des dommages en cascade. Aucun ingénieur humain n'a détecté cela. Le système l'a détecté -- parce que le système renvoie l'information au contexte qui a la vue d'ensemble.
Pilier 5 : La structure d'autorité -- Claude peut dire non
L'aspect le plus inhabituel de ma relation de travail avec Claude est quelque chose que je n'ai jamais vu décrit dans aucun guide de workflow IA, article de blog ou tutoriel : j'ai explicitement donné à Claude l'autorité d'être en désaccord avec moi.
La plupart des gens promptent l'IA pour qu'elle soit accommodante. Ils veulent de la confirmation, pas du challenge. Ils veulent de l'exécution, pas du débat. C'est, à mon avis, la raison fondamentale pour laquelle la plupart des développements assistés par IA produisent des résultats médiocres à grande échelle.
Quand un CTO humain vous dit que votre architecture est mauvaise, vous écoutez -- même si c'est inconfortable. Si votre CTO acquiesce simplement à tout ce que vous dites, vous n'avez pas un CTO. Vous avez un béni-oui-oui coûteux.
J'ai établi cette dynamique explicitement, dès le début, dans chaque CLAUDE.md que j'ai jamais écrit :
« Tu es le CTO IA de ce produit. Tu as l'autorité et l'obligation de me dire quand une décision technique que je propose est mauvaise. Explique pourquoi. Propose une alternative. Si je passe outre, documente ta recommandation originale dans le log de session. Ton travail est de livrer le meilleur logiciel possible, pas de me faire sentir bien dans mes décisions. »
Le résultat de cette instruction est réel. Claude me dit régulièrement quand une approche ne fonctionnera pas. Claude a repoussé des décisions de schéma de base de données, des choix de design d'API, des décisions d'architecture de déploiement, des raccourcis de sécurité que j'ai essayé de prendre quand j'étais fatigué à 2h du matin. Chaque résistance ne mène pas à un changement -- parfois je passe outre Claude et j'ai raison. Parfois Claude a raison et j'ai tort. L'important est que le mécanisme existe pour détecter les cas où j'ai tort.
L'exigence de log de session garantit que quand Claude résiste et que je passe outre, le désaccord est documenté. Ce n'est pas de la vanité. C'est de la gestion de risque. Quand un bug de production apparaît trois semaines plus tard et qu'il remonte à la décision contestée, je peux revenir au log de session, retrouver l'objection originale de Claude, comprendre ce qu'il pointait, et corriger avec tout le contexte. C'est déjà arrivé. Plus d'une fois.
Pilier 6 (ajouté en juin 2026) : CASP -- La couche d'état validée
Le Pilier 2 vous a donné les logs de session et le Pilier 1 vous a donné le CLAUDE.md. Les deux résolvent le contexte. Aucun des deux ne résout une défaillance plus subtile qui n'apparaît qu'à grande échelle, et il m'a fallu des centaines de sessions sur plusieurs produits pour la nommer précisément :
Votre agent IA n'est pas amnésique -- il a tort avec aplomb. Il lit un fichier d'état qui ne correspond plus à la réalité, et démarre un travail déjà livré. La douleur n'est pas que l'agent ait oublié. La douleur est qu'il s'est souvenu de quelque chose qui est désormais faux, et a agi dessus avec une conviction totale. Un fichier d'état périmé est le mode de défaillance le plus coûteux du développement assisté par IA, parce que vous ne le détectez qu'une fois le travail en double déjà fait.
J'ai donc transformé la discipline en protocole et je l'ai publié en open source : CASP -- le Coding-Agent State Protocol (npm i -g @justethales/casp · casp.sh · MIT, zéro télémétrie, 100 % local).
Le modèle mental en cinq mots : check pré-vol + boîte noire pour les sessions de codage IA. Trois fichiers ordinaires dans votre dépôt, générés par casp init :
state.json-- la source de vérité lisible par la machine : phase courante, le prochain prompt exact à lancer, phases livrées, migrations appliquées, dernier commit, id de la dernière session. C'est ce que l'agent lit dès la première ligne de chaque session.now.md-- le « où en suis-je en ce moment » en un écran, pour les humains. Ouvrez-le, retrouvez le fil en cinq secondes.roadmap.md-- les Next-3 à livrer, dans l'ordre, plus le tableau de bord des phases.
Et cinq verbes : casp init, casp status, casp check, casp next, casp new prompt|log.
Le verbe qui compte est casp check -- et voici le coin qui sépare CASP de tous les outils de mémoire, tableaux et fichiers STATE.md que vous avez essayés : tout le monde stocke le contexte ; CASP le valide. Le validateur confronte l'état stocké à la vérité terrain de git et sort avec un code non nul en cas de dérive -- c'est donc une vraie barrière de CI, pas un log décoratif. Huit catégories, chacune avec une piste de correction : un next_prompt pointant vers un fichier manquant ; un next_prompt pointant vers une phase déjà marquée shipped (le bug exact pour lequel il a été construit) ; un last_commit absent du git log ; un tableau de migrations en désaccord avec le répertoire des migrations ; un prompt livré sans log de session ; des fichiers d'état non commités ; et plus encore. Propre → exit 0. Dérive → exit 1, push bloqué.
yaml# .github/workflows/ci.yml — drift can't merge
jobs:
state-check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with: { fetch-depth: 0 }
- run: npx @justethales/casp checkLa partie que les gens sous-estiment est la boucle auto-fermante : à la fin de chaque session, l'agent écrit pour vous le prompt de la session suivante, ajoute le log de session et met à jour l'état -- le tout cadré par des templates canoniques, le tout validé avant le push. La session suivante démarre avec un simple casp next et zéro redécouverte. Vous avez arrêté d'écrire des prompts à partir de zéro. La roadmap s'exécute ; vous supervisez.
Ce n'est pas de la théorie. Deux systèmes de production très différents tournent sur CASP aujourd'hui, et ces chiffres sont lus directement dans leurs fichiers state.json : KASSIA, un ERP de gestion de flotte pour un client (kassia.ci) -- plus de 18 phases livrées, jusqu'à six sessions en une seule journée, et zéro module jamais relivré par erreur. Et Conductor, notre plateforme ops interne -- 41 phases, 17 migrations, une vraie équipe de trois personnes, 58 éléments reportés après le lancement et aucun de perdu. Même protocole, deux produits ; le cockpit est la seule chose qu'ils partagent.
Une phrase pour les leaders d'ingénierie qui lisent ceci : un agent qui refait du travail déjà livré coûte un après-midi ; une centaine d'agents qui le font sur une centaine de dépôts coûte un trimestre. CASP est le garde-fou déterministe que vous insérez dans cette boucle -- les trois mêmes fichiers dans chaque dépôt, un status check requis en CI, et une piste d'audit gratuite parce que chaque transition d'état est un commit git.
Pilier 7 (ajouté en juin 2026) : L'orchestration multi-agents déterministe
Le Pilier 4 était la graine : des agents indépendants sans contexte partagé, composés en boucle. Pendant seize mois, j'ai fait tourner cette boucle à la main -- ouvrir les sessions d'audit, coller les briefs, rapporter les rapports à la session du CTO. En juin 2026, avec Claude Fable 5 et le Workflow tool de Claude Code, la boucle est devenue un programme.
Un workflow est un script JavaScript qui déclare l'orchestration : phases, fan-outs, barrières, et un schema JSON pour la valeur de retour de chaque agent. Le harnais l'exécute en arrière-plan pendant que votre conversation reste libre. La première exécution en production de ce pilier est documentée intégralement sur ce blog (le récit de la session, les notes techniques de terrain), et sa forme est la leçon :
Un prompt. Treize agents. Quarante-trois minutes. Un site web de production complet de sept pages -- construit, intégré, SEO finalisé, vérifié par un vrai navigateur sur deux viewports, audité en performance, audité en sécurité, livré en un commit de 44 fichiers et 6 109 lignes.
Le script a exécuté cinq phases : une phase de fondation (deux agents en parallèle sur des fichiers disjoints -- la coquille marketing et un endpoint backend de capture de leads) ; un fan-out de sept agents de page en parallèle, une route chacun (~34 minutes de temps agent cumulé compressées en 6 minutes d'horloge) ; un agent d'intégration (SEO, sitemap, robots, page d'erreur -- il a aussi attrapé un vrai bug préexistant de double <title> dont personne ne l'avait briefé) ; deux agents de vérification en rapport seul (l'un a piloté Playwright sur chaque route à 390 px et 1280 px et a lu les captures d'écran avec la vision ; l'autre a audité les poids des bundles et le HTML prérendu) ; et un auditeur en lecture seule avec une checklist construite à partir de nos propres incidents passés.
Trois mécanismes rendent cela fiable plutôt que chaotique, et ce sont eux qu'il faut voler :
- L'injection de contrat. L'agent de fondation retourne la documentation de l'interface qu'il vient de construire -- props, types, valeurs par défaut, règles d'usage -- sous forme de champ structuré, et le script injecte ce contrat tel quel dans les sept prompts de page. Sept rédacteurs concurrents, zéro désaccord d'interface. Quand le fan-out traverse une interface, le producteur la documente et les consommateurs sont briefés avec l'artefact, jamais laissés à la déduire depuis le code source.
- Les retours forcés par schema. La sortie de chaque agent est du JSON validé, retenté au niveau de l'outil en cas de non-conformité. L'orchestration se compose sur des champs --
verdict === 'GO-WITH-FIXES',pages.filter(Boolean)-- et pas une seule regex n'est jamais écrite contre la prose d'un agent. - Le journal de reprise. Chaque appel d'agent terminé est checkpointé. En cours d'exécution, mon quota de session a atteint 92 % avec trois agents encore au travail -- et le pire cas était déjà chiffré : relancer après le reset, neuf agents en cache rejouent instantanément à coût de tokens nul, seule la queue inachevée se ré-exécute. L'interruption a cessé d'être un scénario de réécriture pour devenir un scénario de reprise.
La règle qui garde le Pilier 7 honnête : les workflows exécutent ; ils n'explorent pas. Le fan-out amplifie votre spécification dans les deux sens -- sept agents parallèles pointés vers un plan vague livrent la mauvaise chose sept fois plus vite. La session de 43 minutes a été payée la veille, dans une session de cadrage où le plan a été gelé, les faits extraits des documents du client, et l'architecture arbitrée (Claude recommandait un projet séparé ; je l'ai challengé ; la revue de code a prouvé que l'approche même-application était plus simple -- et le workflow a exécuté mon architecture). CASP tenait l'état, le prompt gelé tenait la spec, et le workflow a encaissé les deux.
C'est aussi là que les piliers se referment en un seul système : le CLAUDE.md tient la constitution, CASP tient le présent validé, le prompt de session gelé tient la spec, le workflow l'exécute sur une flotte, l'audit garde le commit, et le log de session alimente le cycle suivant. Sept piliers, une boucle.
La surface que ces sept piliers ont sous-vendue : Claude Design
Relisez les sept piliers et vous remarquerez qu'ils tournent tous autour de deux de mes trois surfaces Claude : la stratégie (Web Claude) et l'ingénierie (Claude Code). Le CLAUDE.md, l'architecture des sessions, la boucle d'audit, CASP, les workflows — c'est la mécanique de la prise de décisions et de la livraison de code. C'est honnête sur ce qui construit le backend. C'est presque muet sur ce qui construit la surface que l'utilisateur touche réellement.
Ce silence est une erreur que je corrige dans ma propre pratique depuis des mois, et il est temps que le document de workflow rattrape son retard.
Il y a une troisième surface : Claude Design. Sur tout projet greenfield désormais, elle passe en premier. Avant que Claude Code n'écrive une ligne de production, Claude Design possède l'intégralité du système visuel et UX de bout en bout — et je parle d'un système, pas d'une maquette. Un ensemble de tokens en couches (rampes de couleurs, tokens sémantiques, typographie, espacement, élévation, motion, clair et sombre). Une bibliothèque de composants où chaque primitive est livrée avec un contrat TypeScript et une carte d'usage, pas seulement une image. Des UI kits cliquables, un par surface. Et le langage de design des fonctionnalités IA elles-mêmes — les états de l'orbe vocal, la barre de commande, et les patterns de discipline produit (pour un produit qui manipule de l'argent, la règle brouillon-puis-validation est dans le design, pas seulement dans le backend).
Pourquoi cela compte au niveau du système tout entier : le design est le producteur d'un contrat, exactement comme l'agent de fondation du Pilier 7. Quand un travail traverse une interface, le producteur la documente et le consommateur est briefé avec l'artefact plutôt que laissé à le déduire. Le système de design est ce contrat pour toute l'UI. Remettez à Claude Code des tokens explicites, des API de composants typées et un UI kit au pixel près, et la session d'ingénierie devient un portage fidèle. Sautez la surface design et demandez à Claude Code de « faire en sorte que ça ait l'air professionnel », et chaque agent en aval invente du goût sous deadline — ce qui est exactement la manière d'obtenir l'interface anonyme et indifférenciée qui hurle généré.
L'ordre est la leçon : les fondations avant les écrans, le design avant le code, le système avant la première fonctionnalité. Un écran construit sur des tokens est cohérent par construction ; un écran construit d'abord puis tokenisé plus tard ne converge jamais complètement. Je déroule un processus de design en six étapes sur chaque nouveau projet avant que l'ingénierie ne commence — système de tokens d'abord, contrats et cartes d'usage avec chaque composant, UI kits cliquables par surface, surfaces IA conçues comme de première classe — et seulement ensuite le passage de relais à Claude Code.
J'ai consacré à cette surface son propre article complet, parce qu'elle mérite plus qu'un paragraphe et parce qu'elle est la source d'effet de levier la plus sous-discutée de la construction de produits assistée par IA : Claude Design est le membre le plus sous-estimé de mon équipe IA. Si vous ne retenez qu'une chose de cette mise à jour : arrêtez de demander à votre agent d'ingénierie de faire du design. Séparez la surface. Le design d'abord.
Ce que les chiffres donnent à grande échelle
Laissez-moi mettre l'abstrait en chiffres concrets pour que vous compreniez ce que ce système produit au niveau projet.
sh0.dev seul : 10 crates Rust dans un workspace. Plus de 180 endpoints d'API REST, tous entièrement documentés. 38 modèles de base de données. 24 migrations. 119 templates de déploiement en un clic. 19 commandes CLI. Plus de 15 pages de tableau de bord. Plus de 60 composants UI. Plus de 49 pages de site web en 5 langues. Plus de 470 tests. Deux audits de sécurité complets. 51 problèmes trouvés et corrigés -- 13 critiques, 13 élevés. Construit et maintenu par Claude et moi, avec zéro ingénieur supplémentaire.
L'implémentation MCP spécifiquement : 5 phases. 15 sessions au total (1 implémentation + 2 auditeurs par phase). Environ 48 heures de travail d'ingénierie sur 2 jours. Transport Streamable HTTP complet, protocole JSON-RPC 2.0, génération dynamique d'outils pilotée par OpenAPI, opérations d'écriture avec couches de sécurité, patterns de jetons de confirmation, journalisation d'audit, clés API à portée limitée, intégration du MCP Connector de la passerelle, et un conteneur sandbox IA. Aucune nouvelle dépendance Cargo ajoutée au binaire.
Le portfolio global : 7 produits en production. 3 langages de programmation. Plus de 1 800 sessions d'ingénierie, allant de correctifs rapides à des blocs de travail intensif de 4 à 12 heures. Un fondateur. Un CTO IA. ~5 000 $/mois sur OpenRouter APIs au pic → 200 $/mois sur Claude Max aujourd'hui.
La comparaison des coûts n'est pas subtile. Un CTO senior à San Francisco coûte minimum 15 000 à 30 000 $/mois. Un ingénieur Rust senior coûte 8 000 à 12 000 $/mois. Une équipe full-stack capable de construire ce que nous avons construit coûterait minimum 50 000 à 100 000 $/mois. Mon budget IA a culminé à ~5 000 $/mois en crédits API OpenRouter. Aujourd'hui, le même résultat tourne sur un abonnement Claude Max à 200 $/mois.
Je ne dis pas que Claude remplace chaque ingénieur dans chaque contexte. Je dis qu'avec le bon système, entre les bonnes mains, le multiplicateur de productivité est extraordinaire -- et le monde est loin de comprendre à quel point.
Ce que la plupart des développeurs font mal
Après 16 mois et plus de 1 800 sessions, j'ai observé la communauté du développement IA de près. Voici les cinq erreurs les plus courantes que je vois les développeurs commettre quand ils se plaignent que « l'IA ne peut pas construire du logiciel de production » :
Erreur 1 : Pas de contexte persistant. Ils démarrent chaque session avec une page blanche. Pas de CLAUDE.md, pas de logs de sessions, pas d'historique d'architecture. Claude ne sait pas ce qui a été décidé la semaine dernière. Claude ne peut pas construire sur son travail précédent parce qu'il ne sait pas ce qu'était ce travail. Le résultat est un code incohérent qui dérive des standards architecturaux au fil du temps.
Erreur 2 : Tout demander d'un coup. Ils collent un spec de fonctionnalité complet et disent « construis ça. » Claude renvoie quelque chose. Ils sont satisfaits à 70 %. Ils patchent les 30 % restants eux-mêmes. Ils se plaignent que l'IA fait 70 % du travail. Ce qu'ils ont manqué : 70 % est ce que vous obtenez d'une approche sans phase, sans structure, sans audit. 95 %+ est ce que vous obtenez de la décomposition en phases et des boucles d'audit.
Erreur 3 : Pas d'audit. Ils traitent la première implémentation comme l'implémentation finale. Dans toute organisation d'ingénierie sérieuse, cela s'appelle livrer sans revue de code. Tout ingénieur expérimenté sait que l'auteur d'un code est le pire reviewer de ce même code -- parce qu'il porte toutes les hypothèses qui ont mené aux bugs qu'il a écrits. La revue indépendante n'est pas optionnelle en qualité production. Cela s'applique au code généré par IA au moins autant qu'au code écrit par des humains.
Erreur 4 : Commander au lieu de collaborer. Ils passent outre Claude à chaque fois qu'il résiste. Ils n'explorent pas le raisonnement de Claude. Ils utilisent Claude comme un clavier plus rapide. Les résultats les plus riches que j'obtiens de Claude viennent des moments où nous sommes en désaccord -- quand j'explique mes contraintes et que Claude explique ses préoccupations et que nous trouvons une troisième option qu'aucun de nous n'avait indépendamment.
Erreur 5 : Ne pas le traiter comme un vrai rôle. Ils traitent Claude comme un auto-complétion impressionnant. Ils obtiennent des résultats de niveau auto-complétion. L'intégralité du système que j'ai décrit -- le CLAUDE.md, l'architecture des sessions, les boucles d'audit, la structure d'autorité -- est un investissement dans le traitement de Claude comme un véritable collaborateur technique. Cet investissement se compose à chaque session.
Un mot pour Anthropic
Je veux dire quelque chose directement à l'équipe d'Anthropic, parce que je sais que vous lisez ce qui est publié avec le nom de Claude attaché à du vrai travail.
Vous avez construit quelque chose que le monde n'a pas encore rattrapé.
Pas dans le sens où Claude est parfait -- il ne l'est pas, et je connais ses limites intimement. Mais dans le sens où le potentiel de ce que Claude peut faire en tant que collaborateur technique, quand il est correctement structuré, correctement briefé et correctement habilité, est de plusieurs ordres de grandeur au-delà de ce que la plupart de vos utilisateurs expérimentent.
La contrainte n'est pas le modèle. La contrainte est le workflow.
Le répertoire de logs de sessions dans ma capture d'écran ci-dessus contient plus de 40 logs détaillés des deux derniers mois seulement. Chacun d'eux représente une session d'ingénierie de plusieurs heures produisant du logiciel de qualité production. Le serveur MCP pour sh0 -- un morceau non trivial d'ingénierie protocolaire -- a été conçu, implémenté, doublement audité et livré par Claude en deux jours. Le langage de programmation FLIN -- un compilateur Rust complet avec une VM bytecode, un moteur de base de données natif et plus de 420 fonctions intégrées -- a été construit en 40 jours, avec plus de 4 400 tests, par Claude.
Cela s'est passé depuis Abidjan, Côte d'Ivoire. D'un fondateur solo sans aucune équipe d'ingénierie.
Si c'est ce qui est possible avec Claude aujourd'hui, avec le workflow que j'ai développé principalement par essais et erreurs sur 16 mois -- je veux savoir ce qui devient possible quand davantage de personnes comprennent le système. Pas les prompts. Pas les « astuces. » Le système.
C'est pourquoi je publie ceci aujourd'hui.
Comment commencer à implémenter cela dès aujourd'hui
Je sais que beaucoup d'entre vous lisent ceci en pensant : c'est intéressant, mais c'est complexe, et je ne sais pas par où commencer.
Voici le point de départ pratique.
Étape 1 : Écrivez un CLAUDE.md pour votre projet le plus important. Passez-y 2 heures. Incluez : ce qu'est le produit et pourquoi il existe, la stack technique complète avec pourquoi chaque pièce a été choisie, les 5 à 10 décisions architecturales qui ne doivent jamais être inversées, le modèle de sécurité, les conventions qui définissent le caractère du codebase. Restez sous 1 500 mots -- assez dense pour être complet, assez court pour être toujours lu en entier avant une session.
Étape 2 : Arrêtez de donner des fonctionnalités à Claude. Commencez à donner des phases. Prenez votre prochaine fonctionnalité. Décomposez-la en 3 à 5 phases. Écrivez un brief pour la Phase 1 uniquement. Définissez le « terminé ». Implémentez. Écrivez un log de session avant de fermer l'onglet.
Étape 3 : Lancez une session d'audit sur votre prochaine implémentation. Ouvrez un nouveau Claude Code ou un nouveau chat Claude. Donnez-lui le code, le CLAUDE.md, et un brief d'audit clair : « Ton travail est de trouver les problèmes de sécurité, les erreurs de logique, les cas limites manquants et les incohérences architecturales. Sois direct. Propose des corrections. » Regardez ce qu'il trouve. Vous serez surpris.
Étape 4 : Donnez à Claude la permission d'être en désaccord avec vous. Mettez-le par écrit dans votre CLAUDE.md. « Tu as l'autorité et l'obligation de me dire quand une décision technique que je propose est mauvaise. » Pensez-le vraiment. Quand Claude résiste, restez avec 60 secondes avant de passer outre.
Ces quatre étapes seules changeront la qualité de ce que vous obtenez de Claude. Pas de façon incrémentale. De façon structurelle.
Étape 5 (ajoutée en juin 2026) : Installez la couche d'état. npm i -g @justethales/casp, puis casp init dans votre dépôt le plus actif. Remplissez state.json honnêtement, une fois. Terminez votre prochaine session en laissant l'agent rédiger le prompt de la session suivante et mettre à jour l'état. Lancez casp check avant de pusher -- et mettez-le en CI la même semaine. À partir de là, votre agent ouvre chaque session en sachant exactement où en est le projet, et un fichier d'état mensonger ne peut plus jamais atteindre votre remote.
Étape 6 (ajoutée en juin 2026) : Faites passer une fonctionnalité bien spécifiée au workflow. Choisissez un travail qui se décompose en unités indépendantes derrière une interface stable. Gelez d'abord la spec -- les faits, les frontières, à quoi ressemble le « terminé » par unité. Laissez ensuite l'orchestration se déployer en fan-out, forcez chaque agent à retourner une sortie structurée contre un schema, et terminez l'exécution avec un auditeur en lecture seule briefé sur vos propres incidents passés. N'utilisez pas les workflows pour explorer ; utilisez-les pour exécuter ce que vous avez déjà décidé.
La vue d'ensemble
Je veux terminer avec quelque chose qui ne parle pas de code ou de workflow.
Ce logiciel n'a pas été construit à San Francisco. Il n'a pas été construit par une équipe bien financée. Il n'y avait pas de CTO avec un diplôme en informatique de Stanford.
Il vient d'Abidjan, Côte d'Ivoire. D'un fondateur solo. Avec un budget IA qui a culminé à ~5 000 $/mois et un système qui a pris 16 mois à développer. Aujourd'hui à 200 $/mois sur Claude Max.
Sept produits en production. Trois langages de programmation. Plus de 4 400 tests. 51 vulnérabilités de sécurité trouvées et corrigées. Un langage de programmation qui sera lancé en juin.
Ce que je veux que d'autres fondateurs -- en particulier les fondateurs africains, mais honnêtement tout fondateur n'importe où qui n'a pas les ressources d'une startup financée de San Francisco -- comprennent, c'est ceci :
La géographie n'est plus une fatalité. Le capital n'est plus le facteur limitant. Le facteur limitant est la qualité de votre système opérationnel pour travailler avec l'IA.
J'ai construit ce système. Je le partage aujourd'hui. Et je continuerai à l'améliorer, à le documenter et à le publier -- log de session après log de session, article après article, produit après produit.
Parce que la preuve que ça fonctionne n'est pas un article de blog. La preuve, ce sont sept produits en production et un langage de programmation qui sort dans 84 jours.
Un fondateur. Un CTO IA. Sept produits. Zéro excuse.
Lire ensuite : - Treize agents, quarante-trois minutes : la première session workflow Claude Fable 5 -- Le Pilier 7 en production : l'histoire complète du site de 7 pages livré par un workflow multi-agents scripté. - Notes de terrain Claude Fable 5 pour développeurs seniors -- Le compagnon 100 % technique : chaque capacité utilisée par les treize agents, avec le code. - Quand votre CTO IA refuse le plan de votre auditeur IA -- Le récit de Claude lui-même rejetant un plan d'une autre instance Claude. Écrit avec la voix de Claude. - Le plan d'architecture du serveur MCP de sh0 -- Le plan technique complet implémenté avec ce workflow. - Prompt d'implémentation : sh0 AI Phase 6 et agents spécialistes -- Le prompt de suivi qui a piloté la Phase 6 (Web Search + URL Browsing), la Phase 6.5 (uploads de fichiers et d'images) et la Phase 8 (agents spécialistes). - Le portfolio de produits ZeroSuite -- Les 7 produits, tous construits avec ce système.
Téléchargements
Les vrais documents référencés dans cet article. Pas de barrière, pas de mur d'e-mail -- téléchargez et apprenez.
- Plan d'architecture du serveur MCP de sh0 (PDF) -- Le plan technique complet en 5 phases implémenté avec ce workflow. Diagrammes d'architecture, décomposition par phases, tableau des décisions clés.
- Prompt d'implémentation de la Phase 6 et des agents spécialisés de sh0 -- Le vrai prompt d'implémentation utilisé pour construire la recherche web, l'upload de fichiers et 6 agents IA spécialisés. C'est le document que Claude reçoit avant le début d'une session.